


Image for illustrative purposes
AI AND ML IN DATA ANALYSIS
As we move towards greater application of, and reliance on, Artificial Intelligence and Machine Learning (AI/ML) systems, it’s worth noting that there are some activities where they perform well, and some where they perform poorly. Recent experiences with large language models (LLMs) such as ChatGPT (1) have shown that it is going to be some time before the machines take over from humans in analyzing anomalous condition monitoring data and are able to extrapolate from experience: looking backward to predict the future.
I had heard that AI/ML tools can do all sorts of clever stuff, so I asked ChatGPT if it could help with some bushing data I’d collected from an on line condition monitor: it seemed like a good idea as ‘What’s the worst that could happen?’ The case was a real one, with the data for one bushing plotted below, Figure 1, showing leakage current rms magnitude hourly; the data shows anomalous behavior – but what does it mean?
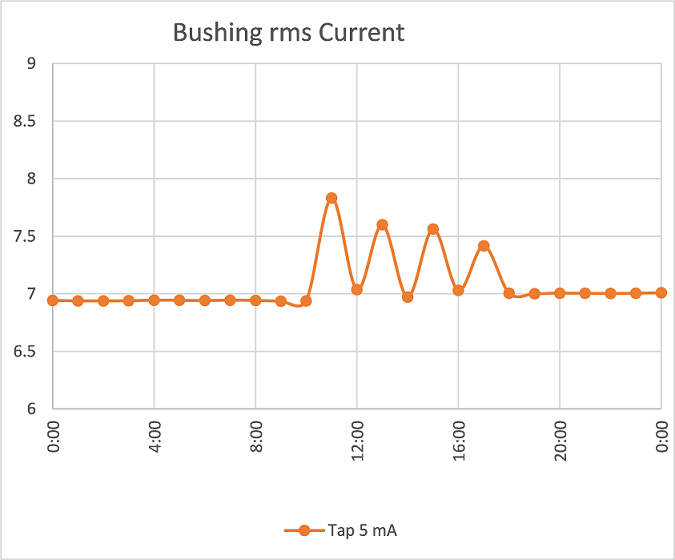
Figure 1: Raw Bushing rms Current Data Recorded hourly
If you read the limitations for ChatGPT on the landing page it does say:
- “May occasionally generate incorrect information”
- “May occasionally produce harmful instructions or biased content”
- “Limited knowledge of world and events after 2021”
So we proceeded with caution as we are dealing with some HV bushings and ‘What’s the worst that could happen?’ is actually quite bad: catastrophic failure of the whole GSU power transformer with associated consequences: fire, safety and environmental issues, system disruption and so on.
The data in Figure 1 is real, and disturbing: why would a current rise then fall, repeatedly? Could it be a problem with the monitor itself? What does it mean? the question I asked ChatGPT was: “If I am monitoring a bushing and the leakage current rises sharply, but then falls rapidly back to nominal, then rises again, and falls again, then stabilizes close but just above nominal, what should I do?”
I must admit that I wasn’t expecting much in the way of a response and what I got started with the expected generic response that there ‘could be a problem which needs investigation’ genre, as shown in Figure 2:

Figure 2: Response as expected – broad statements of a possible problem
But what I was not expecting was the caveat that came with it, given in Fig 3.

Figure 3: ChatGPT caveat in terms of condition monitoring data analysis
After basically saying “I don’t know what this is” in Figure 2, ChatGPT suggests checking with a qualified electrical engineer/technician: this seems to be an eminently sensible idea. Whatever expertise ChatGPT has, it does seem to ‘realize’ its own limitations. And checking with SMEs is exactly what we did when we reviewed the original data: checking with people who know what they are doing. If you are interested in what the data means, and what happened next, I’d be happy to share: suffice to say it’s an unusual case but the bushing remained in service for more than 12 months more.
When successful, AI/ML can look like magic: performing well at picking out faces in a crowd, say, or analyzing lots of data extremely rapidly and consistently, but they can also show bias, make mistakes, and reach unsupportable conclusions (2). Problems such as:
- ‘Giraffing’: where the system detects giraffes in supplied pictures even though there are no giraffes present
- Bias: usually based on the original data being biased, for example, looking for a reliable transformer and preferring Manufacturer X to Manufacturer Y based on limited failure statistics which don’t reflect the real world
- Misapplication: training a tool to distinguish between pictures of cats and dogs, and then trying to identify a llama…
- Not having a good indication of why the AI makes the decision it does: it’s worth noting the case of an X-ray interpretation tool which performed well, but which made decisions based on the type of X-ray machine that was used, rather than the detailed content of the X-ray (3)
The cause of these mistakes may be through inappropriate ‘training’, or application to data which is not related to the original data, or which are the result of inflated expectation in the user, and so on. What is common to AI/ML models is that they build on example data – base data, training data, historic data – to identify/classify/analyze ‘new’ data. And, to quote the language specialist Noam Chomsky who has an insight into the use of language to train and apply AI systems:
“There is a notion of success ... which I think is novel in the history of science. It interprets success as approximating unanalyzed data.”
What is common to AI/ML models is that they build on example data – base data, training data, historic data – to identify/classify/analyze ‘new’ data.
And therein lies the problem – an AI/ML tool is usually very poor at extrapolating from whatever data it has ’seen’ in order to make sense of what it hasn’t seen previously.
It is an interesting side-note that an estimated 95% of the benefits of AI/ML can be achieved through standard statistical and data analyses on the raw data, but that is to miss the point that the other 5% may be vitally important (4). We don’t know until we look! BTW, side-note 2: the idea that we just get more data and throw it all at a bigger AI/ML system is usually a bad idea, wasting time and effort and resources: it’s best to start with a small system which can grow and build on success (5).
So, we need to understand the data we have available: what did we train the AI/ML on, and does a new piece look at all like that? There are examples of AI/ML classifier tools which, in the first instance, do not try to classify new data but make a check as to whether the new data looks like previously available data, and calculates an ‘out of distribution’ (OOD) value (6). If the OOD means it doesn’t look like something we’ve seen before, ask for a relevant specialist to check: that is, ask someone who has domain knowledge, experience and can interpret data.
What else? Context is extremely important, as demonstrated by the following two examples of composite DGA monitors, giving a representative ppm value for combustible gases dissolved in transformer oil. In Figure 4 we can see a gently rising trend over several days, and a sudden rise from about 75ppm to >120ppm in a few hours. In the second case, a relatively flat trend suddenly steps up from ~20ppm to almost 120ppm in a few hours.
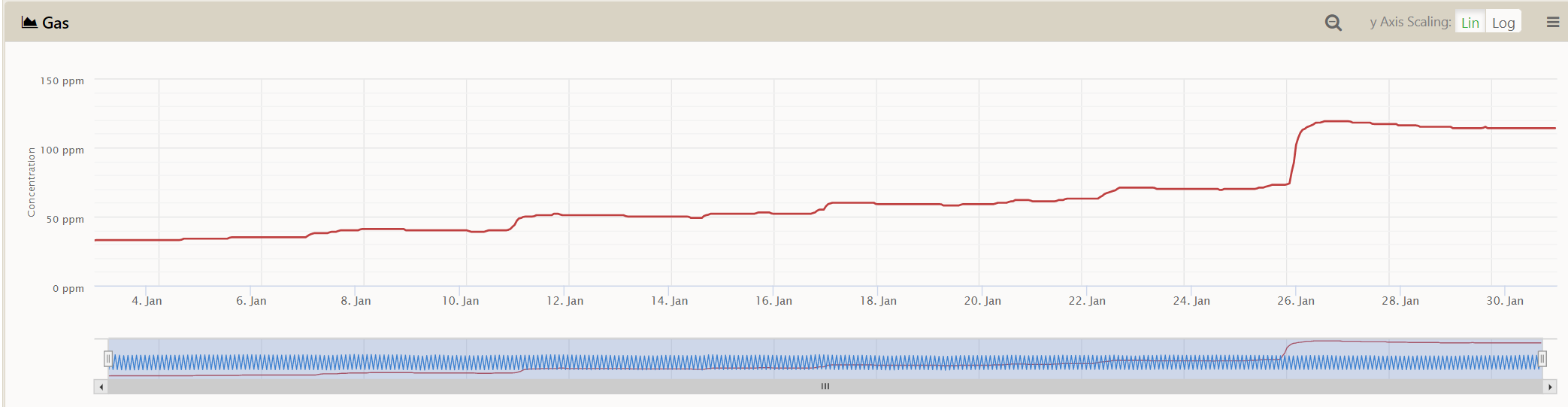
Figure 4: Composite DGA with a rising trend and a sudden step change
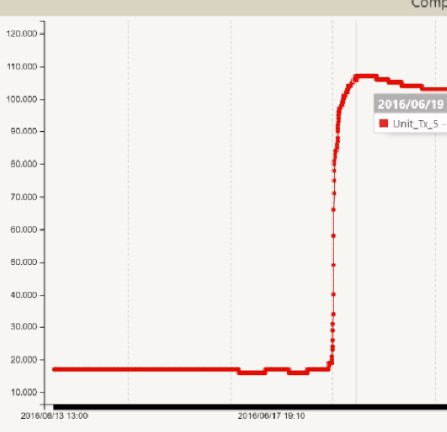
Figure 5: Composite DGA with a ‘flat’ trend and a sudden step change
The two DGA cases, are, in fact, sister transformers: same manufacturer, both 48MVA, both over 30 years old, rarely fully loaded but some indications of overheating in the DGA and FFA levels. The transformer in Figure 4 was taken out of service a few days later, tested using standard tests, and an internal inspection confirmed severe overheating and likely imminent failure of LV lead connections – which had been undersized from the initial manufacture: if it had stayed in service, it could have failed catastrophically. And the transformer in Figure 5? It was returned to service after a prior maintenance outage, but with the cooler return valve closed: subsequently, there was a temperature alert as the cooling was not functioning, and the rise in monitored DGA was a result of the cooler valve being opened and fresh oil reaching the DGA sensor: the transformer was actually de-energized at the time. How do we get all of that type of information, context, and insight into an AI system? That is going to be a challenge.
At DistribuTech this year, there was a significant number of companies offering AI/ML tools as part of their offerings: OEMS, consultants, service companies, data companies, and so on. What is perhaps most encouraging is that many of them understood quite clearly that while they may find interesting relationships or trends within supplied data, they also need the capability of industry experts to give meaning to the findings. This is a challenge when we are losing capability through retirement or career changes, and have fewer people than needed entering the industry each year. And, of course, new industry individuals will take some years before becoming the SME’s of the future. AI/ML can fill some of the gap, but not all of it – over time it may be that AI/ML gets more adept and the cases where real experience is needed are fewer, but the ‘edge’ cases aren’t going away. And with the growth in DERs, and the increase in the need for condition monitoring, there is a corresponding need for humans who understand the data and can look for answers which may lie outside the box: such as would apply to the bushing in Figure 1.
The work of Tom Rhodes and colleagues at Duke Energy is highly relevant – applying AI/ML to support the engineers, not replace them: use the tools to identify where SMEs can most profitably spend their time. Initially the pure data scientists complained about the data ‘It must be wrong as it doesn’t fit our models’, but after some ‘learning’ on both sides, the resulting hybrid approach provided great value to the organization (7). And it may be that, over time, the number of cases which the AI/ML passes over to the SMEs reduces, as the AI/ML learns, but that, too, will take time.
So, in the interest of experimentation, I did ask ChatGPT many other questions, but one sticks in my mind: “Can you give me some anagrams of ’Transformer Bushing’?”. It shouldn’t be too difficult to rearrange 18 letters into something interesting for a system with the language skills of ChatGPT, and it came up with several, but my favorite was “The Grim Buffoons Runes”. This may seem pretty good, but it has a couple of extra letters, meaning it fails the basic definition of what an anagram is… sometimes you have to get the simple stuff right, like counting letters, before doing something difficult like rearranging them into new words.
Conclusions: AI/ML can only work on what it has been ‘shown’ and fill in the gaps. It is very poor at generating ‘new’ knowledge. The role of SMEs in data analysis is not going to go away in the near future, and we still need someone who knows what is going on, and can look at the data, the context and the details simultaneously to come up with something ‘outside the box’.
References
-
https://chat.openai.com/
-
https://abad1dea.tumblr.com/post/182455506350/how-math-can-be-racist-giraffing
-
https://www.npr.org/sections/health-shots/2019/04/01/708085617/how-can-doctors-be-sure-a-self-taught-computer-is-making-the-right-diagnosis?
-
https://www.kdnuggets.com/2018/04/dirty-little-secret-data-scientist.html
-
https://hbr.org/2019/02/how-to-choose-your-first-ai-project
-
https://ieeexplore.ieee.org/document/9615946
-
“Practical Machine Learning Applications”, T. Rhodes et al, ‘CIGRE Grid of the Future’, Providence, RI, 2021



 Security in Substations")




