


Image for illustrative purposes
DIGITAL TWINS
Introduction
The emergence of digital twin (DT) technology in the power sector has improved the grid operators’ confidence to visualize the asset state in real-time and provide decision-support that particularly aligns with the smart grid objectives. According to Conseil International des Grands Réseaux Electriques (CIGRE), a DT is the virtual replica of a physical asset that can foster a dynamic shift in managing its operational efficiency and reliability in real-time. It is useful when the equipment (or process) changes over time, or the data associated with this change can be captured and analysed. This brings the necessary traction for the use of DT in the transformer industry to revolutionize the traditional approaches towards design optimization, monitoring, and asset management.
A transformer DT differs from its simulated model by its forecasting abilities over time-series feedback using bi-directional communication between the physical and virtual assets. However, errors in scaling-down of the physical asset, abstraction of the phenomena under investigation, and obscure objectives can significantly affect its performance. Overall various factors contribute towards the design of a transformer DT which requires a wide range of data, devices, protocols, and expertise thereby increasing its cost and complexity. The focus of CIGRE joint working group A2/D2.65 is to address this reality gap and provide recommendations for the future development of such technologies.
A transformer DT differs from its simulated model by its forecasting abilities over time-series feedback using bi-directional communication between the physical and virtual assets.
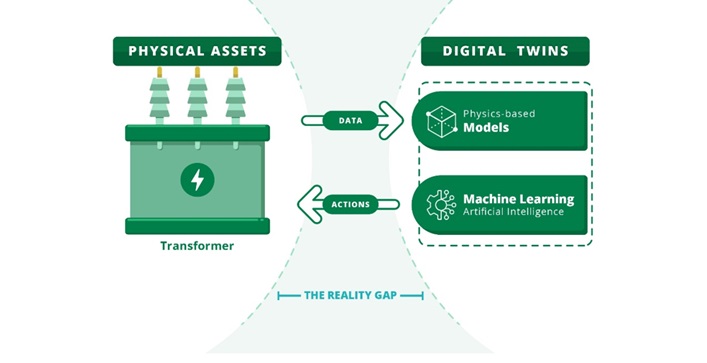
Figure 1: CIGRE’s realisation of transformer digital twins
Building an AI-driven digital twin
The present-day smart grid is a complex cyber-physical labyrinth comprising of various IoT devices, advanced robotics and automation. The integration artificial intelligence and such technologies with traditional practices such as dissolved gas analysis (DGA)-based fault analysis for example, can provide more nuanced predictive analytics.
Dataset at a glance
A transformer DT should have access to its feature database integrated with supervisory control and data acquisition (SCADA) systems where information travel securely through IoT (internet of things) pipelines in to computational spaces that are either cloud or edge based for modelling and analytics. Some utilities also build comprehensive internal databases that are representative of various operational scenarios of their assets by combining, for example, IEC TC 10 database with condition monitoring data to enhance its future use. The user can visualize their asset and fleet information through charts, graphs, and even geographical maps. The user can either examine the asset characters on static and dynamic scales, add-up various assessment functions for analytics, or predict remaining life.
Data preparation: pre-processing, normalization & mining
Transformer data may be sparse, structured or unstructured, static or dynamic, and non-comparable i.e. lacking normalization. Data pre-processing refers to the initial cleaning and transformation of raw data into useful format. It includes managing missing data by removing redundant or inconsistent information and imputing missing fields. Normalization can be achieved by strictly defining the upper and lower limits of attributes or diving the numerical value of features with their IEEE and IEC limits [1]. Managing unclear attributes and arranging data into structured formation increases the full potential of various data mining algorithms viz., regression, classification, clustering, and association to effectively explain the system behaviour. In data-driven modelling terms, regression refers to the process of quantifying relationship between two or more variables; whereas, classification is finding different classes from a dataset that share a common attribute. Similarly, association is the co-occurrences of values for different variables; whereas, clustering is the act of finding groups of similar observations within a dataset [2].
Feature extraction and selection
Feature scaling through extraction and selection is a significant step in AI-driven model frameworks to reduce data collection cost, avoid computational bias and optimize model performance. Feature extraction is the logical or rule-based creation of sub-features from an existing dataset. Whereas, feature selection refers to the act of choosing a set of features or attributes from the parent dataset based on the quality, continuity, impact, significance etc. Dimensionality reduction is another helpful technique to reduce the feature dimensions of a parent dataset by removing irrelevant information without compromising its distinctive significance.

Feature scaling through extraction and selection is a significant step in AI-driven model frameworks to reduce data collection cost, avoid computational bias and optimize model performance.
Knowledge extraction through AI
Artificial intelligence (AI) refers to the learning ability of machines to simulate human intelligence and perform complex tasks, particularly when it is beyond the human scope. Whereas, machine learning (ML) is the development of a model’s capacity to predict better outcomes based on its training on the past data by using one or more algorithms and with additional learning to address uncertain scenarios [3]. Often AI sub-fields e.g. deep learning and neural networks overlap to form new technologies to address other advanced challenges. For example, generative AI is another subset of AI that creates new content, data, or solutions autonomously by learning from the existing data. Popular generative AI model such as Chat GPT excel in natural language processing tasks to produce coherent and relevant text upon receiving related inputs and prompts. There is a similar rise in the use of generative adversarial network (GAN) for synthetic image generation and synthetic minority oversampling technique (SMOTE) or borderline-SMOTE (B-SMOTE) for numerical data generation. The latter is of particular interest in transformer industry due to its ability to generate reliable synthetic dataset for compensating various inconstancy issues. Figure 1 shows a simplified summary of various AI sub-fields that finds diverse application in energy sector.
Often AI sub-fields e.g. deep learning and neural networks overlap to form new technologies to address other advanced challenges.
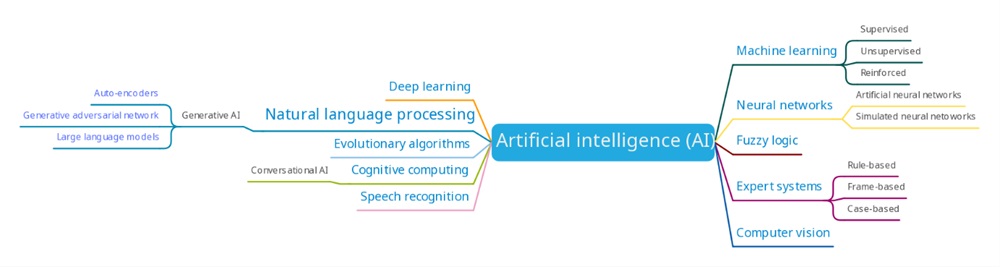
Figure 2: Commonly used AI sub-fields in solving energy problems
There is an additional weak description on the dividing boundaries between some methods within an AI sub-field. For example, linear discriminant analysis (LDA) is a supervised machine learning approach that is a classifier and feature selection tool. Similarly, Random Forest (RF) algorithms are classifiers, regressors, as well as model optimizers. Additional examples are illustrated by Figure 2 to represent the use of various algorithms in mining (solid lines) and feature scaling (dashed lines). Therefore, it is imperative to understand the problem objective, data characteristics, computational affordability, and cost before choosing a suitable method.
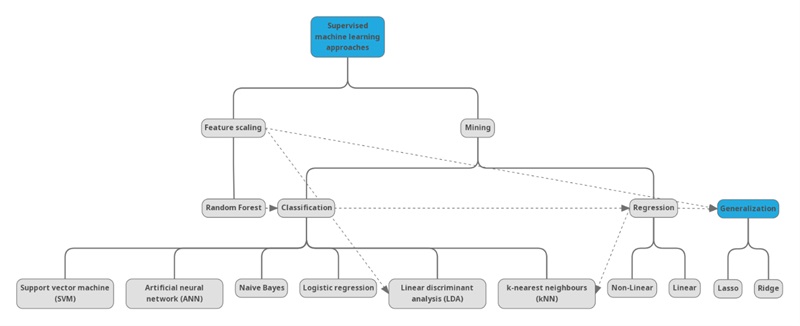
Error and accuracy
Most comprehensive frameworks use a combination of various models known as ensemble to improve accuracy and reduce errors. It also leverages boosting and bagging of data to reduce error and uncertainty tolerance during training of the dataset. The trade-off between bias and variance in choosing any method depends on its generalization impact on the model performance. Additional factors such as strategic positioning of algorithm stack (model learnability) is especially decisive in designing an AI-driven framework such as a multi-layered neural network to perform particular jobs while avoiding overfitting risks. Often the use of robust libraries within a programming environment can help to achieve this task.
Data security and privacy
It is pivotal to ensure data integrity while protecting its privacy, particularly in AI models that handle sensitive or proprietary information. According to the General Data Protection Regulation (GDPR), pseudo-anonymisation of data can dissociate its personal identity such as test results from the data subject (e.g. nameplate information, manufacturer etc). This can ensure that AI-driven training of datasets for a transformer DT can still allow the model to learn and make accurate predictions without compromising security. The choice between popular pseudo-anonymisation techniques such as encryption and tokenisation depend on requirement, robustness of method, storage requirement, and computational resources.
Reliability assurance
The reliability of any AI-driven transformer DT focuses on the integrity of its model, training data-quality, interpretability and reproducibility. Sparse and low-quality data not only lowers accuracy but also restricts model scalability. Developing model ensembles with adequate stacking of algorithms for pre-processing and feature scalability can also overcome the risk of overfitting during development. This enormously improves the efficiency of AI-based mining algorithms and promotes multi-objective delivery suitable for real-world scenarios in optimum cost.
Deployment
The global expert opinion on the deployment model of transformer DT is divided between cloud, edge, and on-premise. For instance, cloud computing can be seamless, robust, and highly scalable but with latency and data-privacy issues. Conversely, edge computing can offer better data processing in close proximity of the device and robustly automated decision support by triggering alarms or sending alerts. However, the choice does not depend on the advantage of one method over another. Instead, what really drives this discussion is the balance between scalability, cost, and resources for infrastructural support.
Digital twins predicting transformer health index
Various organizations use an in-house or proprietary health index algorithm to rank transformers based on its reliability, risk, replacement and/or refurbishment needs. This requires an extensive usage of nameplate data, operational and maintenance history, various test and inspection observations, expert opinion etc [4], [5]. Often health index algorithms are based on non- ubiquitous frameworks that align well with PAS 55 and ISO 55000. For example, a health-index classification of “good”, “bad”, “moderate” transformers may use data from DGA, moisture, breakdown voltage, interfacial tension, acidity etc., of oil and furan analysis. A deeper classification on the same may require additional information on tap changers, bushings, physical observations, maintenance history etc.
Depending upon the asset manager’s requirements these algorithms may provide a decision support with a perpetual risk of producing misleading information with low-integrity input. In case of its application on real-world transformers, the training data should be clean, useable, heterogenous and pseudo-anonymized. The training model should assure robustness and accuracy of knowledge extraction using best features or sub-features. There should be sufficient know-how on parameter evaluation, tuning, and AI model validation before its release on unseen and real-world data to avoid over/under-fitting risk. Finally, the user should be able to engage with the physical asset by uploading data and visualizing the analytics through an interactive interface. This will ensure the user (or asset manager) to take necessary actions on the physical asset and immediately update its status to observe future changes. Furthermore, the data transmission between the core model and the user-interface should be encapsulated within well-defined security protocols to avoid cyber vulnerabilities.

An AI-driven approach towards health indexing is definitely a loose use-case of transformer DT that requires additional efforts (in terms of model stacking, data storage, and management) to experience its full potential. Therefore, an obvious matter is to decide if a single DT reflecting health index is sufficient for all transformers in a fleet, or not? Also, if the DT is relatable enough?
An AI-driven approach towards health indexing is definitely a loose use-case of transformer DT that requires additional efforts (in terms of model stacking, data storage, and management) to experience its full potential.
In case of transformer DT, accuracy is not merely a reflection of the model's adept predictive capabilities but an illustration of a calibrated balance between adhering to training data and maintaining adaptability to new and real-world data scenarios. The interpretability and reproducibility of DT outcomes will determine its relatability and reliability. Furthermore, it is difficult to propose that a single DT can mirror the status of all transformers in a fleet, considering even physical twins may behave differently. Therefore, successful deployment and industrial scale transformer DT offering health index will not only depend on various practical considerations discussed above, but also on its calibration towards uncertainty tolerance and data influx, particularly if data sources vary. There is a wide scope of investigation on the sensitivity analysis on the impact of data availability rate on the predictive accuracy of such DTs. A summary of the full potential of an AI-driven transformer DT with reference to the knowledge shared is proposed below.
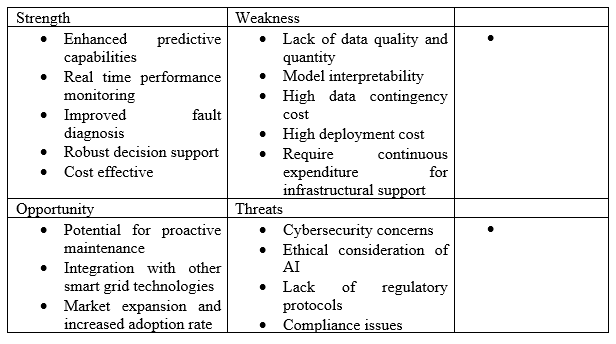
Conclusion
An AI-driven transformer digital twin can adapt to various smart grid objectives by real-time analysis, predictions, and bi-directional communication between the physical and the virtual asset. However, the choice of AI methods will depend on the handling strategies between static and non-comparable data. The accuracy and performance of model can improve by structed stacking and addressing the bias-variance trade-off between various methods based on data complexity. Maximizing return on investment (ROI) for an AI implementation can be challenging and involves do- or buy-decisions. This would mean that the asset manager must decide whether to leverage in-house know-how on building AI models or use existing solutions. This cost and expertise for such customization depends on the downtime impact assessment, internal budgets and user adoption rate. Based on the evident findings, adoption of transformer DT can be a game changer for the smart grid operators.
References
[1] K. Benhmed, A. Mooman, A. Younes, K. Shaban, and A. El-Hag, “Feature Selection for Effective Health Index Diagnoses of Power Transformers,” IEEE Transactions on Power Delivery, vol. 33, no. 6, pp. 3223–3226, Dec. 2018, doi: 10.1109/TPWRD.2017.2762920.
[2] “CIGRE TB 292 Data mining techniques and applications in the power sector.”
[3] A. Subasi, Practical Machine Learning for Data Analysis Using Python. Academic Press, 2020.
[4] CIGRE WG A2.49, “Condition assessment of power transformers,” CIGRE, Technical Brochure 761, Mar. 2019.
[5] A. Naderian, S. Cress, R. Piercy, F. Wang, and J. Service, “An Approach to Determine the Health Index of Power Transformers,” in Conference Record of the 2008 IEEE International Symposium on Electrical Insulation, Jun. 2008, pp. 192–196. doi: 10.1109/ELINSL.2008.4570308.
Sruti Chakraborty is the co-founder of Seetalabs and condition monitoring researcher with a PhD in Chemical Engineering from Malaviya National Institute of Technology-Jaipur, INDIA. Her area of operation includes digital transformation of traditional condition monitoring practices and develop low-cost solutions for risk management and failure mitigation of industrial assets including power transformers. She is hugely passionate about optimizing asset reliability and reducing data complexities in transformer industry using artificial intelligence (AI). She is the working member of CIGRE WG A2/D.65 and A2/D1.67 where she is contributing towards developing recommendations to solve various AI-driven data handling and analytics bottlenecks. She also hosts periodic tech-talks with industry professionals on various challenges and solutions in the field of clean technology, AI, cyber-security, and smart grids.







